Цифровой гербарий МГУ: четыре точки входа
Немногие знают о том, что на самом деле Цифровой гербарий МГУ доступен по четырем разным адресам. Каждая из точек доступа имеет свой арсенал средств поиска и представления информации. Именно многообразие возможностей работы с нашими образцами является приоритетом в развитии нашей цифровой коллекции.
1) https://plant.depo.msu.ru/
Операционная версия, или "боевая база". Наш основной портал, в котором пользователи имеют возможность искать образцы с помощью расширенного поиска, поиска по этикеткам, таксономического дерева. Скоро внедрим и геопоиск. Здесь через личный кабинет есть возможность что-то исправлять, дополнять и редактировать (А.П. как куратору). Сюда программисты заливают большие табличные массивы новых данных (например, этикетки, геопривязки, новые сканы, русские названия и прочее).
2) https://plant.depo.msu.ru/open/
Открытая версия. Она нужна для индексации поисковыми системами и быстрого простого поиска по массиву. Выдача идет в виде иконок, можно сохранять адреса запросов. Создан также для снижения нагрузки на боевую базу при интернет-запросах. Вообще, штука удобная и многие, разобравшись, ищут сканы именно через нее. Это элементарно быстрее.
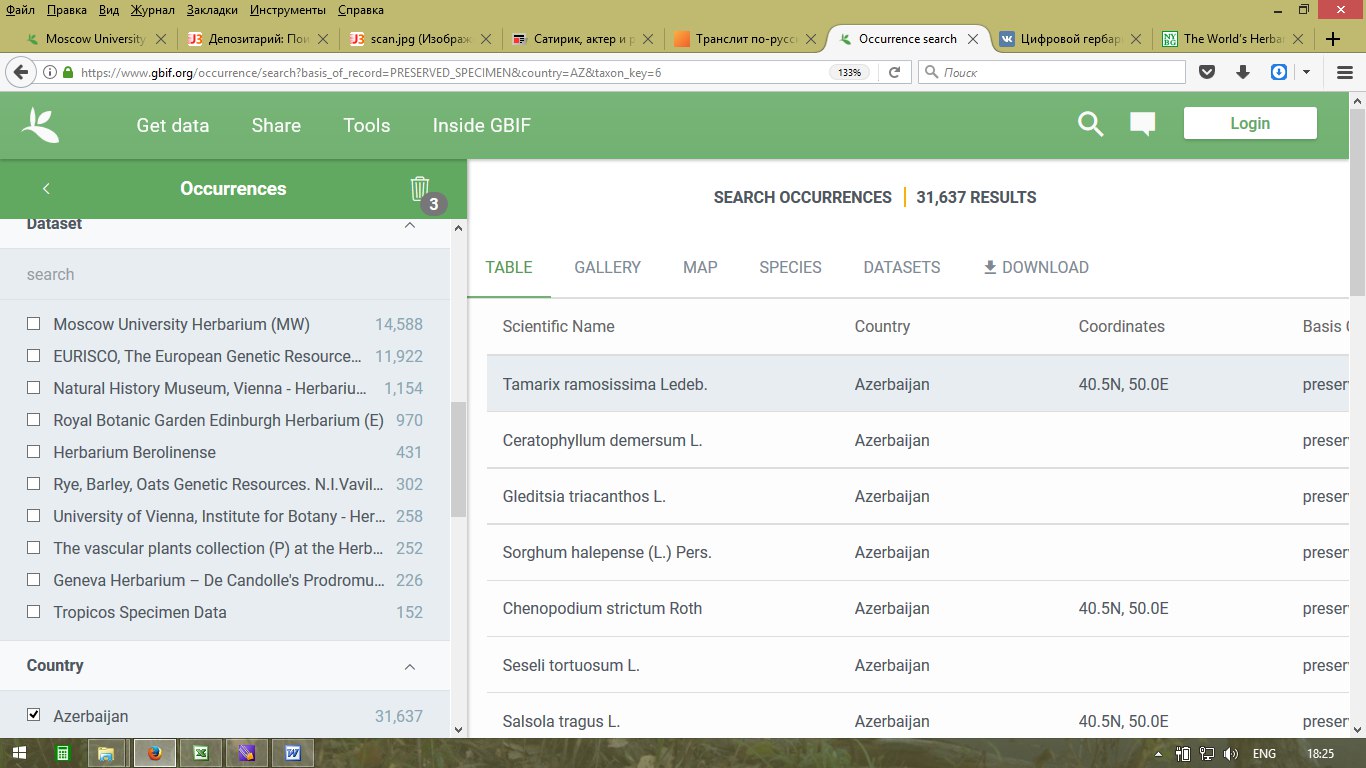
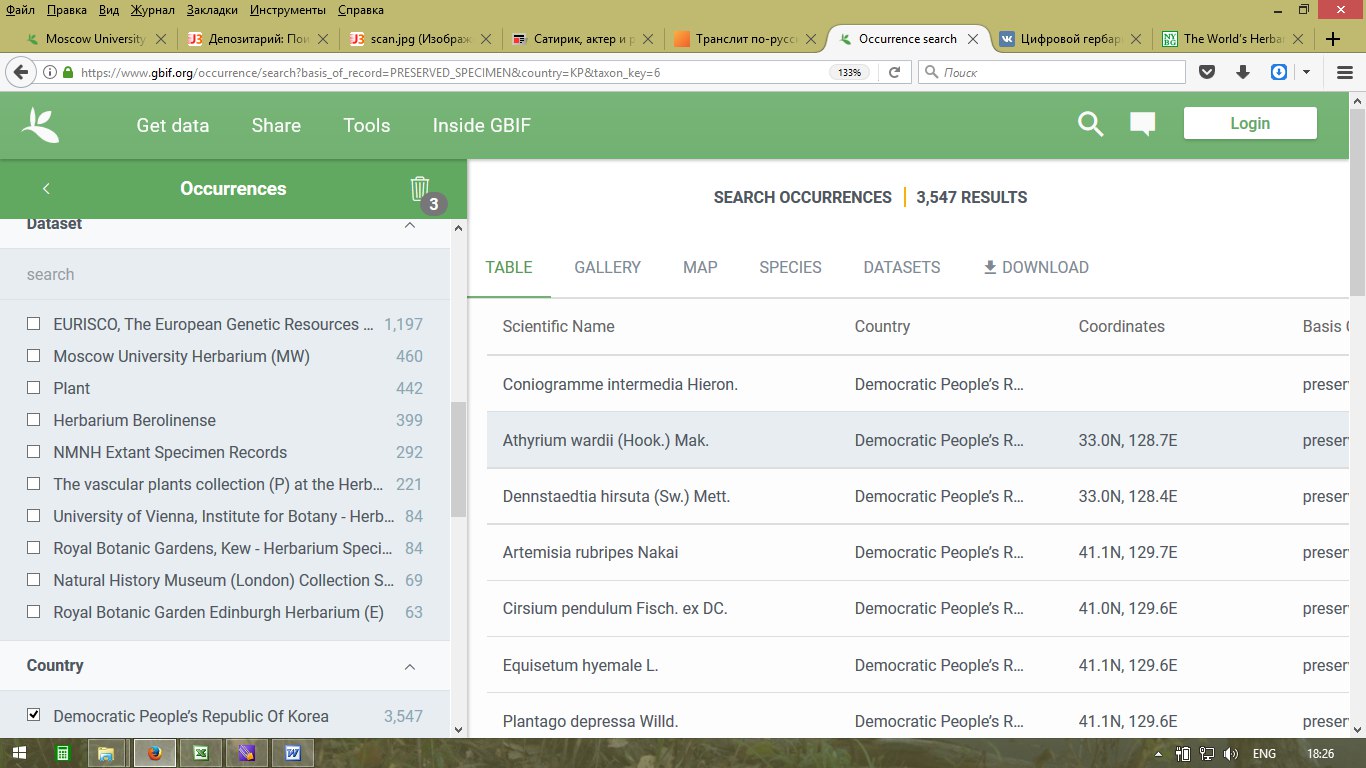
3) https://www.gbif.org/dataset/902c8fe7-8 … 24fed36303
Адрес нашего Цифрового гербария в GBIF – агрегаторе данных по биоразнообразию мира. Раз в неделю, начиная со 2 ноября 2017 г., мы заливаем в GBIF наш датасет целиком. Поскольку это большая навороченная система для оперирования гетерогенными пространственными и таксономическими данными о биоразнообразии мира, то здесь создан целый арсенал фильтров и картографических визуализаций для того, чтобы что-то у нас найти. Но главная задача нашей публикации через GBIF в другом: теперь, даже если мы храним всего два образца какого-нибудь африканского растения, исследователь неминуемо будет их видеть и учитывать в своих исследованиях. Что уж говорить о Северной Евразии – территории, с которой мы являемся крупнейшим поставщиком данных. Осталось лишь все образцы аккуратно привязать к карте. А так статистика налицо: из 874 млн. записей в GBIF – 809 тыс. наши 
4) https://yandex.ru/images/
Яндекс.Картинки. Неожиданная, но очень важная точка доступа. Почему? Все дело в технологиях распознавания текста на картинках (OCR). Яндекс, проиндексировав 786 тыс. сканов Гербарий МГУ, прогнал наш массив через процедуру OCR. Все печатные символы, слова и предложения, которые программа распознала на этикетках, теперь используются для индексации изображений. Так стало возможным искать сканы образцов, текст которых еще не внесен в базу этикеток. Это огромный шаг вперед в деле бесконечного структурирования миллионного (без малого) массива Цифрового гербария МГУ. Скорее всего, вслед за Яндексом, мы также в будущем применим элементы OCR для первичной сортировки массива по коллекторам и географии.
Итак, четыре точки доступа, не считая обыкновенного текстового поиска в поисковиках, где мы целиком индексируемся. Не будем загадывать, но, скорее всего, Google.Images станет пятой




















{kind=link}